Expanding on my recent post on Serverless Data Engineering with AWS Glue, note that Athena is another AWS managed service from which we can perform queries on an S3 data lake, connected via the query-able AWS Glue data catalog, using the full set of standard SQL, including complex joins, subqueries, string manipulations, and window (aka analytic) functions. Athena’s query engine built on Apache Presto. Based also on the Apache Hive Metastore, Athena can also query a data catalog and even create external tables. An external table means a query-able pointer to files in S3, because neither Athena nor the Data Catalog themselves store any data records. Both Glue and Athena can be used to instantiate external tables. A data engineer is more likely to do that from Glue, perhaps as part of scheduled data loading into S3, whereas a SQL data analyst is more likely to do it from Athena, perhaps as a way to pre-join data, aggregate it, or perform a calculation on a dataset just once rather than during each query.
Athena databases are even more abstract than tables in that they are merely folders in which to organize Athena tables. As such, cross-database joins are no more complex than within a database. It is simply a matter of identifying the right foreign key.
What else is interesting about Athena?
- Unlike either Presto or Hive, it is serverless, which eliminates a layer of infrastructure to manage.
- It is integrated with other serverless tool such as S3, Glue, and Quicksight, thus a good enabler of AWS’ overall serverless analytics proposition.
- Athena is designed for a schema-on-read setting, so that source schema changes can be accommodated with minimal refactoring. Whereas with schema-on-write, a source schema change may require substantial re-engineering of a downstream data model and it’s supporting ETL, with Athena, it may be, if anything, just a change to a query.
- Athena workgroups can be used to manage and segregate various teams of analysts with differing access needs and, as necessary, to set limits on their data processing either at the workgroup level or at the individual query level.
Hands-on:
My last blog post was more focused on Glue, but did include writing a SQL query in Athena. Picking it up from there, we will…
- Manage and re-use queries using Saved Queries
- Save as View (from a written query):
- Create Table as Select (CTAS)
Saved queries

In the above screenshot of the query editor page, note the ‘Save as’ button. Providing simple, meaningful, and ideally standardized, query names and descriptions goes a long way towards productive collaboration among team members within an Athena workgroup.
Anyway, if you are following from within the Athena console, click it and provide a name and description. Either way, next step is to click on the Saved queries tab.
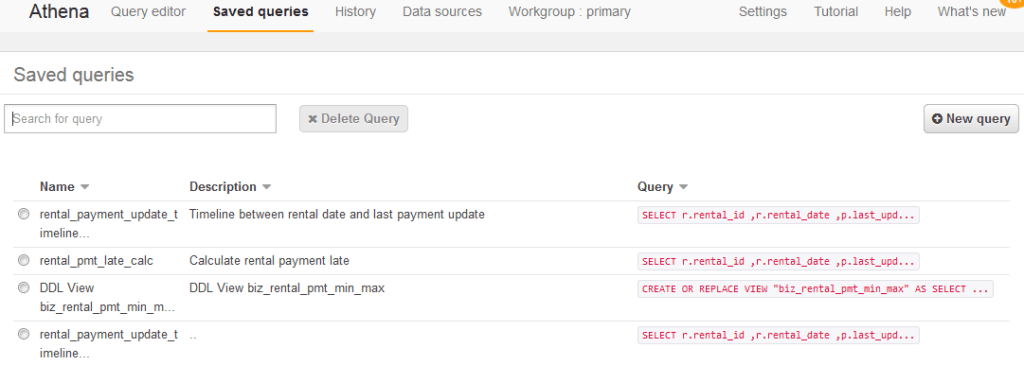
Note in the above screenshot…
- Queries to be saved must (of course) be named and must also be given a description. Once on the Saved queries page, any erroneous or unnecessary saved query can be deleted.
- Clicking on ‘New query’ simply brings us back to the query editor
Create View from Query
When a query accomplishes something that has potential for re-usability, creating a view from it is a standard way of storing it for re-use while masking the queries code from new queries written using it. The screenshot below is a simple example of this, using the dataset we already created in Glue.
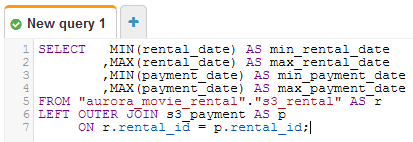
- Clicking Save as View, naming it biz_rental_pmt_min_max, we see the view in the screenshot below. Clicking the elipsys to it’s right, we see the following screenshot.
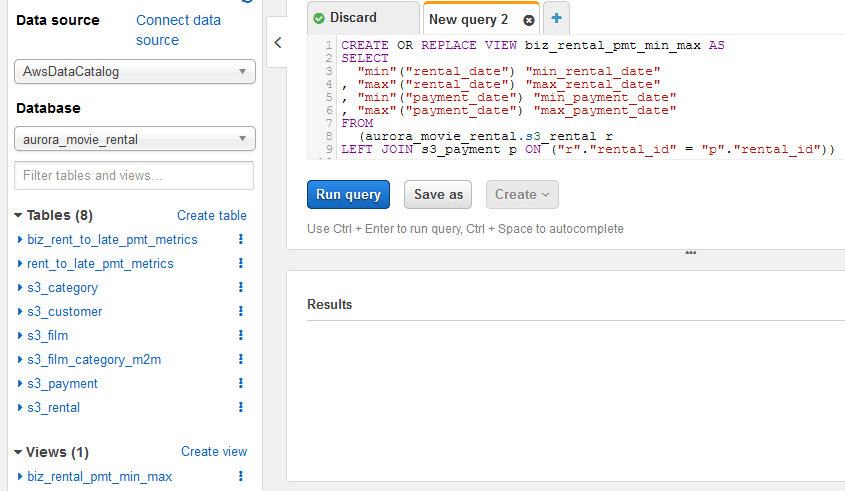
- Note the following
- Standard SQL DDL syntax: “Create… View as Select”.
- On the left pane, the new view is available for use in queries
As you will remember from the previous posting, the AWS Glue Catalog does not distinguish between tables and views and will, in fact, catalog a view from a source data repository as though it is a table, unless excluded by the view object’s name from the Glue Crawler. With that, note that the Glue Data Catalog does not recognize a view created in Athena.
Create Table from Query:
Do we want Athena users to create tables? Depending on the Athena user, the answer in the context of self-service analytics — or disciplined Athena usage — is yes. Suppose a data engineer uses Glue to instantiate data in the Data Catalog while automating the ETL into S3 based on the known, documented business requirement. Now, as the business requirement evolves, it becomes apparent that a certain additional one-time, or at least infrequent, data transformation is necessary, and when combining the size of the dataset with the complexity of the needed transformation, simply creating a new view is insufficient. First off, the view may take too long to return data. Secondly, if this is a one-time or infrequent transformation (thus needing little or no new data going forward), then our Amazon bill will remain smaller if we avoid re-running the same logic over and over simply to get the same answer from the data, which is what a view, or a query, does. So yes, creating tables in Athena can make sense, and next we will discuss what is involved. Simply for demo purposes, the query in the screenshot below represents an important query that creates more overhead on each run than we want to keep paying to Amazon. Although we should also assume that the people creating the Athena tables understand the ramifications of creating tables, remember that Athena workgroups can be governed with data processing limits.
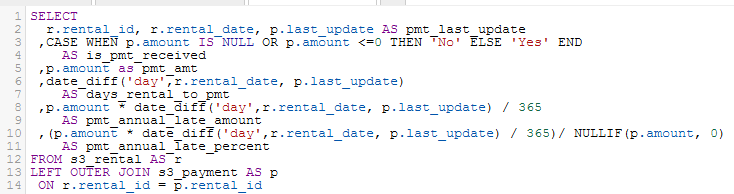
After running the above query, we do the following
- Go to S3 and create a folder in which the table’s data records will be stored. We will look at S3 in a moment.
- Click Create / Create Table from Query and see this screenshot.
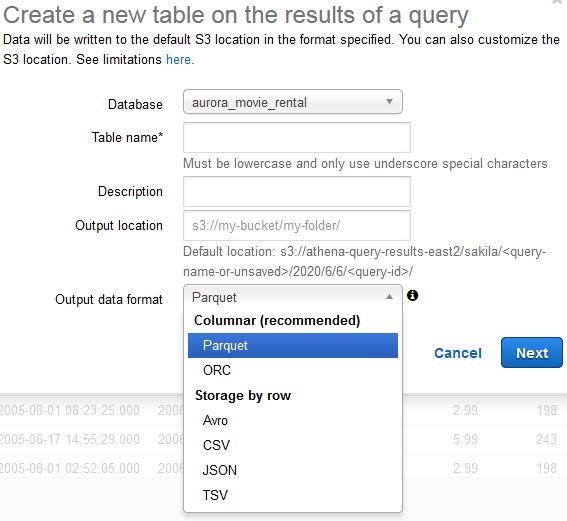
In the above screenshot notice…
- We must enter a database name (but did not have to in creating a view). This is our hint that this new external table will be recognized in the Glue Data Catalog.
- In keeping with our self-service context, we add the ‘biz…’ prefix to the table name to inform Athena workgroup members that this table is created as part of self-service, and does not have recurring incremental loading.
- An S3 folder must be specified wherein the table’s data records will be stored. In the screenshot below, notice the S3 folder path. We have created a special ‘biz’ S3 folder to organize all self-service objects created by this Athena workgroup and, of course, have trained out table-creating users to specify it in their created tables.
- Output data formats
- Columnar (recommended): Parquet and ORC. Both are compressible, and partition-able, thus both can radically improve query performance, with the important benefit of drastically reducing our Amazon Bill.
- Storage by Row: Still popular formats, but far efficient to query, thus potentially far more expensive in Amazon. CSV, perhaps because of its simple human-readability and Excel compatibility, remains popular, but creating tables in S3 as CSV’s can be expensive and slow.
- Because users will most likely query just a few columns from this table, we will choose Parquet. If it were a wider table, this would be even more important.
The following screenshot shows the new table and it’s DDL. Note that all that is new in this DDL is the code above the ‘…AS SELECT’ line. The code is always available for each table via the right ellipsis / Generate Create Table DDL.
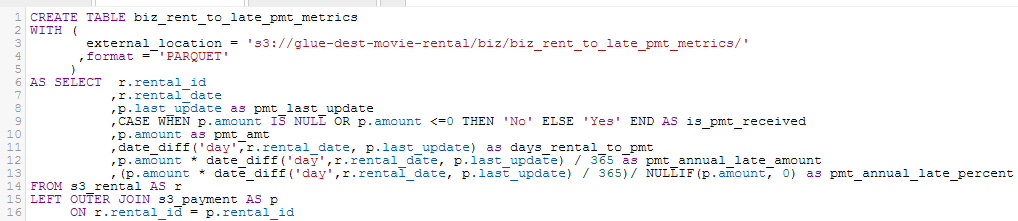
Conveniently, the above SQL DDL code was auto-generated. Now that it has run, let’s see it as stored in S3 in the screenshot below.
Options for Create Table As Select using other data formats, with explicit partitions and compression, is available in AWS documentation here.
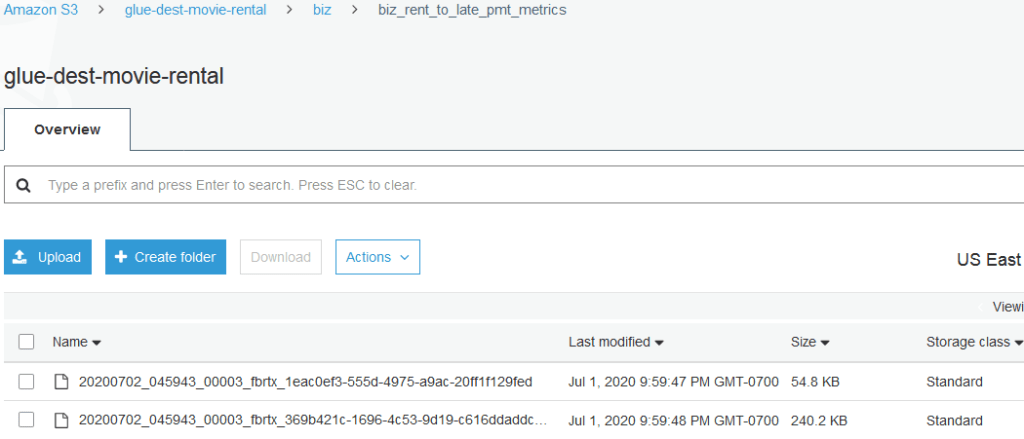
Note the following…
- In S3, the database name and table name are simply folders
- The files are the table’s Parquet partitions, generated by Athena.
Now that we’ve created the table in S3, do we now need to re-run a Glue Crawler in order to catalog this table? No, we do not. Athena, like Glue, can directly create tables in the Glue Data Catalog, so that an Athena user, not necessarily needing time from a Glue data engineer or direct access to Glue, can create and immediately begin using new tables, which can easily be compressed and partitioned for high-performance usage.
Conclusions on Athena:
When something works well, it’s a good sign when it begins to feel simple. Under the covers, Athena is, on the one hand, a scalable query engine that performs SQL queries against files of diverse storage formats, and from diverse data repositories, once they are stored in the S3 data lake, via the Glue Data Catalog. As we have also shown, it is also a convenient engine for DDL and ad-hoc loading of new, already compressed and partitioned tables in those same diverse formats and have them automatically catalogued for immediate usage. Although it is beyond the scope of my demonstration here, Athena can also create and query JSON files, which will also prove useful for self-service analytics freed from the formal of a dedicated ETL capability. Importantly, Athena makes the capabilities simple and accessible to analysts familiar with SQL and curious about Athena, but not necessarily interested in ETL, data architecture, or servers per se.
Not bad for self-service analytics! So, what will Athena not do? Whereas Athena, created by Amazon for AWS cloud usage, is designed exclusively for serverless analytics in AWS, Presto is capable of querying a significantly longer list of on-premise or in-cloud relational databases, as well as the flat file formats supported by Athena, Presto can also leverage AWS Glue as a data catalog, or just use Apache Hive metastore, but without AWS Glue Crawlers. Presto, while not serverless, is available in AWS via Elastic Map Reduce, EC2, and of course, anywhere else that it is instantiated in the cloud or on-premises.
In closing, Athena plays a central role in Amazon’s serverless analytics offering. If you need to query S3 and you don’t already have Redshift (thus Redshift Spectrum) up and running, Athena seems like a very good choice.
In an upcoming post, I intend to demonstrate Amazon Quicksight’s also-serverless, use of Athena to accelerate data preparation for visualization and reporting on data stored in an S3 data lake.
If this this post answered some questions you had about Athena, then it has served my objective in writing it. If so, let me know either by commenting on this blog post, or commenting, or simply clicking ‘LIKE’ on this item in my LinkedIn feed to it. Thank you!
