As defined at cloudflare.com, a virtual machine, is “software that imitates a complete computer system [my note: an operating system, applications, network interfaces; everything except hardware]. It is isolated from the rest of the machine that hosts it and behaves as if it were the only OS on it…” A container, which does not have its own OS, “contains both an application and all the elements the application needs to run properly”
Serverless computing is defined as “…a method of providing backend services on an as-used basis. Servers are still used, but a company that gets backend services from a serverless vendor is charged based on actual usage, not a fixed amount of bandwidth or number of servers.”
So, serverless is different from VM’s and containers in that users of serverless computing not only avoid managing the operating system, as with a container, and not only also avoid managing the hardware, as with a a VM; they even avoid managing the application / platform and instead, simply use it and scale it up or down to whatever level is necessary.
Why go Serverless?
Why avoid the management of an hardware, operating system, and applications? First, we have far less work to do either creating and supporting infrastructure ourselves or waiting for others to do it. Instead, we can focus our efforts on quickly using applications/platforms to build solutions, secure them and provision them to users. Secondly, not to say that serverless computing is absolutely less costly, but it does requires far less investment, and thus risk, up-front, because serverless is purchased ‘pay-as-you-compute’. The serverless vendor is well paid only after we turn up the knobs for our solution to continue running large data volumes through it, continue doing extensive processing, or continue supporting heavy usage by many users, all of which seem preferable to traditional architectures. In reality, good ideas often crash and burn, so many will appreciate the serverless value proposition in which a much lower initial investment is made on infrastructure and labor. If our serverless initiative gains only a little traction, we keep it deployed with the scaling knobs (and costs) turned down unless and until usage increases. If it bears no fruit at all, we turn off the services, immediately stop paying, and the serverless vendor provisions the same machines, OS and applications to another customer. So, the value proposition of serverless is a good example of the general proposition of cloud-native computing.
Serverless Analytics
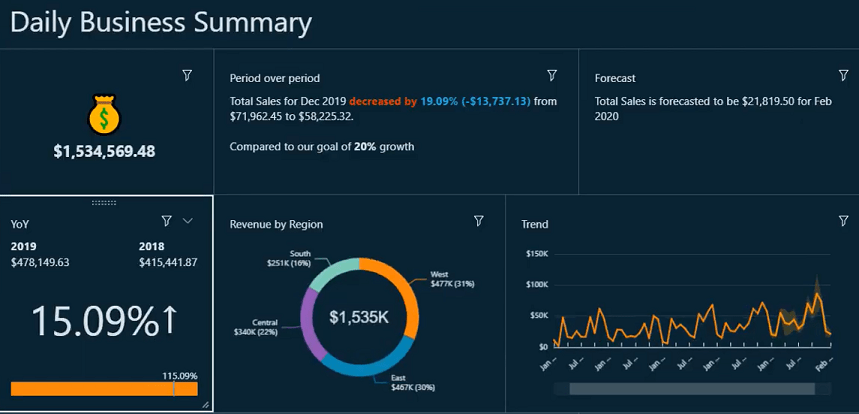
Serverless analytics is simply serverless computing with applications and platforms focused on analytics, data visualization, reporting, and the associated data management and processing. Although the work of analytics is obviously different from other development work, the underlying value proposition of serverless computing remains the same.
So, in this context, my series of updates on AWS Serverless Analytics Fundamentals begins. By fundamentals here, I mean the fundamental analytics associated with business intelligence: data cataloging, ETL, data visualization, reporting, and the various opportunity for self-service analytics along the way. Although the series is also applicable to cloud MPP data warehouses, and to provisioning data for data science, both of those topics, per se, are beyond our scope here.
Architectural Use Case
For data that we store in an S3 data lake, we will demonstrate selected AWS Serverless tools to do all of the following:
- Using AWS Glue, crawl most or all tables and/or views in an operational database in Amazon RDS (Remote Database Svcs) to automatically catalog them, load some or all into an S3 data lake, then re-crawl (re-catalog) them once landed in the data lake: Per Gartner, “Data Catalogs are the New Black…”
- Again with Glue ETL, leverage PySpark, SparkSQL, Pandas, or iPython SQLMagic to transform the data, instantiate and load it into a data presentation layer
- Use Amazon Athena to immediately query the data lake with the full library of ANSI SQL, the gold standard.
- Demonstrate Amazon QuickSight, an relatively new cloud platform to build, deploy, and secure compelling data visualizations and reports
- All the while…
- Minimizing or eliminating redundant storage of data downstream from the data lake
- Eliminating the infrastructure work of procuring, configuring, patching, upgrading and supporting a machine, OS, or application.
- Along the way, we will also explore to what extent each of the above components can be used to support and sustain self-service analytics.
- Finally, we will consider what our demonstrations indicate in relation to some best practices around Agile, CI/CD (continuous integration/continuous deployment), DataOps, and scalability.
In demonstrating all of the above, we will gain insight about how these AWS serverless analytics tools can help us continue delivering valuable insight to customers both more quickly and at lower cost.
[Late Entry]: The next entry in this series, emphasizing AWS Glue, is here.
I welcome comments and suggestions, and will try to work them into my upcoming posts in the series.

One thought on “AWS Serverless Analytics: The Promise”